This is a prototype implementation of the sparse tensor algebra compiler theory and contains known bugs, which are documented here. If you find additional issues, please consider submitting a bug report.
Input a tensor algebra expression in index notation to generate code that computes it:
|
Tensor |
Format
(Level Formats)
TACO represents tensor formats as compositions of the following per-dimension level formats:
Dense levels store the size of the dimension
$(N)$ and encode the coordinates in the interval $[0, N)$.
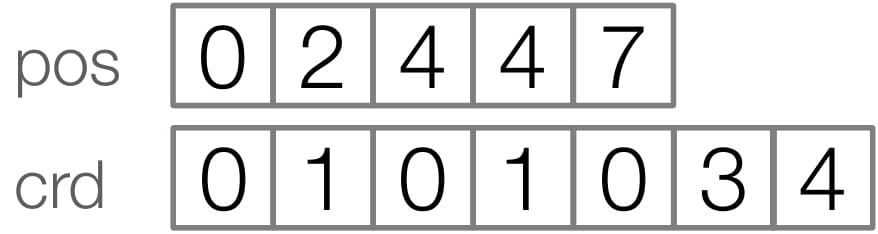
Compressed levels store coordinates in a
segment of the $\texttt{crd}$ array, with segment bounds
stored in the $\texttt{pos}$ array.
Singleton levels store individual
coordinates in the $\texttt{crd}$ array.
Some level formats also come in different variants that either can only store unique elements (U) or may store duplicate elements (¬U). More details can be found here. TACO also supports non-row major tensor formats such as CSC. You can define non-row major tensor formats in the web tool by dragging the drop-down menus to reorder dimensions. |
|---|


|
Scheduling Command
Arguments
|
|---|
/* The generated compute code will appear here *//* The generated assemble code will appear here *//* The complete generated code will appear here */The generated code is provided "as is" without warranty of any kind. To help us improve TACO, we keep an anonymized record of all requests submitted to the TACO online server.